We often need to find and delete duplicate rows from the Oracle table due to many reasons in the database. We need to delete to clear off the data issues often. There are many ways to delete duplicate rows but keep the original.I will be showing off a few faster methods to achieve it in this post. I will show the method where rowid is used and the method where rowid is not used. Please note that you must identify all the columns that make the row a duplicate in the table and specify all those columns in the appropriate delete statement in SQL
How to delete duplicate rows from Oracle
Here are some of the ways to delete duplicate rows in an easy manner
(A) Fast method but you need to recreate all oracle indexes, triggers
create table my_table1 as select distinct * from my_table; drop my_table; rename my_table1 to my_table;
Example
SQL> select * from mytest;ID NAME------1 TST2 TST1 TSTSQL> create table mytest1 as select distinct * from mytest; Table created. SQL> select * from mytest1;ID NAME-------2 TST1 TSTSQL> drop table mytest; Table dropped. SQL> rename mytest1 to mytest; Table renamed. SQL> select * from mytest;ID NAME-------2 TST1 TST
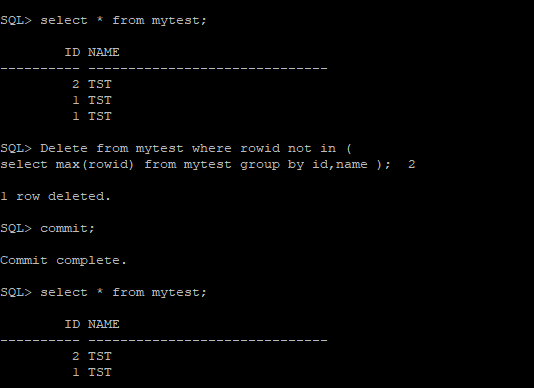
(B) How to find and delete duplicate records in Oracle using rowid. The below example shows one column. if you have deleted based on two-column ,you can specify two column
Delete from my_table where rowid not in ( select max(rowid) from my_table group by my_col_name );
(C) Use oracle self-join to delete duplicate rows
DELETE FROM my_table A WHERE ROWID > (SELECT min(rowid) FROM my_table B WHERE A.key_values = B.key_values);
(D) Use exists clause
delete from my_table t1 where exists (select 'x' from my_table t2 where t2.key_value1 = t1.key_value1 and t2.key_value2 = t1.key_value2 and t2.rowid > t1.rowid);
(E) delete duplicate records by using oracle analytic functions
delete from my_table where rowid in (select rid from ( select rowid rid, row_number() over (partition by column_name order by rowid) rn from my_table) where rn <> 1 )
So as shown, there are many ways to delete duplicate rows in the tables. These commands could be handy in many situations and can be used depending on the requirement. Please always make sure we have a backup available before executing any statements. We should also first find the duplicate using the query and then verify it before committing it
How to find duplicate records in Oracle using rowid
select * from my_table
where rowid not in
(select max(rowid) from my_table group by column_name);
So First find the duplicate using the above query, then delete it and the deletion count should be the same as the row count of the query above. Now run the find duplicate query again. If no duplicate then we are good to commit
Please look at the below article to have a deep dive into Oracle Sql
Oracle Sql tutorials : Contains the list of all the useful Oracle sql articles. Explore them to learn about Oracle Sql even if you know Oracle Sql
Oracle interview questions : Check out this page for Top 49 Oracle Interview questions and answers : Basics , Oracle SQL to help you in interviews.Additional material is also provided
where clause in oracle : Restricting the data set, where clause, what is where clause in sql statement, comparison operator’s
single row functions in Oracle : Check out this to find out Single row functions in sql,Oracle data functions,Numeric functions in sql ,Character function in sql
oracle sql queries
blog.oracle.com