What is Parallel Execution in Oracle database
Parallel execution in oracle allows a single SQL statement to be executed by a multiple processes executing concurrently on different CPU’s. It increases throughput by utilizing more resources (Memory, CPU & I/O).It uses a pool of instance background processes (query slaves) .Based on Parallel Execution you are able to use more system resources like CPU or I/O at the same time for a specific operation. As a consequence the total runtime can significantly decrease.
In short
1.To speed up access to data by using multiple processes
2.To maximize machine resource usage in query processing
3.To reduce elapsed time by increasing resource usage
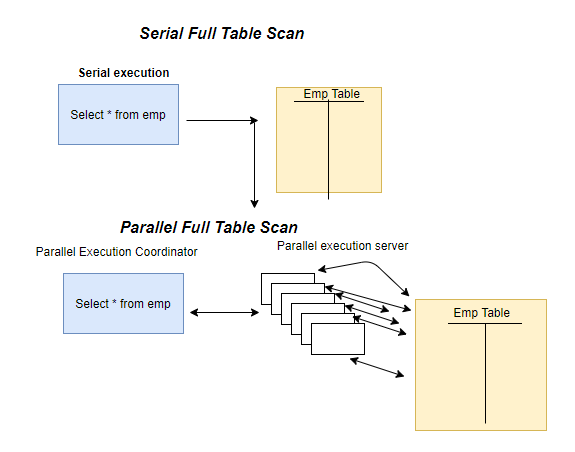
How Parallel executions Works
Step 1 -Query is submitted and parsed, parallel plan is considered
Step 2 -If parallel plan is chosen, shadow process becomes query coordinator (QC).
Step 3 -The QC divides the workload among producer slaves using ROWID ranges.
Step 4 -Producer slaves read the data directly from disk and place it on table queues ready from consumer slaves.
Step 5 -Consumer slaves only used when sort operation is required, otherwise data is passed directly to the QC for output.
The communication and data transfer between the processes is based on queues. The communication structures are part of the shared pool:
PX msg pool
Communication area for the parallel query processes
Size depends mainly on PARALLEL_EXECUTION_MESSAGE_SIZE, PARALLEL_MAX_SERVERS and the actually used parallel query slaves
PX subheap
Memory structure with additional parallel query related information Usually small compared to “PX msg pool”
Blocks that are read via Parallel Execution are always read directly from disk bypassing the Oracle buffer pool
In short
1.Query coordinator parses the query and partitions work between the slaves
2.Query Slaves do the work and pass results back to the QC
3. Table Queues (TQ) are used to move data between processes
4.Query Coordinator passes results back to user
5.Query Slaves are background processes
What is Query Coordinator
1.The server shadow process of the session running the parallel query
2.Parses the query and determines degree of parallelism
3. Controls the query and sends instructions to the PQ slaves
4.Determines the work ranges for the PQ slaves
5. Produces the final output to the user
What is Parallel Query Slave
1 Controlled by the Query Coordinator process (hence the name Slave)
2. The processes which do most of the work in a parallel query
3. Slaves are allocated in slave sets, whichact as either PRODUCERS or CONSUMERS
4. A slave set may act as both PRODUCER and CONSUMER at different stages within a query
How to enable Parallel Processing
(1)First the appropriate init.ora parameters should be set
PARALLEL_EXECUTION_MESSAGE_SIZE:This parameter determines the size of the communication buffer between the different Parallel Execution processes.
In order to avoid a bottleneck it’s recommended to set this parameter to 16384.
PARALLEL_INSTANCE_GROUP: This parameter can be used in RAC environments in order to restrict Parallel Executions to a sub set of the existing RAC instances. This is for only pre 11gR1 and 11gR1
PARALLEL_MAX_SERVERS:With this parameter the maximum number of simultaneously active slave processes can be specified. If more slaves are requested at a certain time the requests are downgraded and a smaller parallelism is used.
PARALLEL_MIN_SERVERS:This parameter specifies how many slave processes are created during database startup. If more slaves are needed, they are created on demand.It’s recommended to keep this parameter on the default of 0 in order to avoid unnecessarily started slave processes.
PARALLEL_FORCE_LOCAL : True This set the parallel slave on the instance only where query was fired
PARALLEL_THREADS_PER_CPU:
This parameter influences the DEFAULT parallelism degree (see below).
In order to avoid overload situations with DEFAULT parallelism it’s recommended to set this parameter to 1.
PARALLEL_ADAPTIVE_MULTI_USER:
When this parameter is set to TRUE (what is default for Oracle 10g) parallel executions may be downgraded by Oracle even before PARALLEL_MAX_SERVERS is reached in order to limit the system load. If you need to guarantee maximum parallelization (like during reorganizations or system copies) it is advisable to set this parameter to FALSE. During normal operation the value TRUE should be okay because resource bottlenecks can be avoided.
(2) Table/Index DEGREE storage parameter can be modified to enable them to user parallel query
Segment level
Parallelism on segment level can be activated with the following command:
ALTER TABLE <table_name> PARALLEL <degree>; ALTER INDEX <index_name> PARALLEL <degree>;
In order to check the parallelism for a certain segment, you can use the following selection:
SELECT DEGREE FROM DBA_TABLES WHERE TABLE_NAME = '<table_name>'; SELECT DEGREE FROM DBA_INDEXES WHERE INDEX_NAME = '<index_name>';
(3) Parallel hint /*+ PARALLEL(table_alias,4) */ used in query, where 4 is the degree of parallelism, best to leave degree blank and let the optimizer choose.
select /*+ PARALLEL(JN, 10) */ count(*) from ar.RA_INTERFACE_LINES_ALL jn;
(4) parallel keyword for DDL statements
Operation that can be run parallel
Parallel Query
Table/Index Scan
Nested loop Join and Sort Merge Join
Union All
Group by and order by
Distinct
Union,Intersect and Minus
Aggregation
Hash Join
Parallel DML allows to run DML operations in parallel
UPDATE
DELETE
INSERT
Parallel DDL allows to run DDL operations in parallel
CREATE INDEX
ALTER INDEX REBUILD
CREATE TABLE AS SELECT
Disadvantage of Parallel Execution
The following disadvantages are possible:
(1)Resource bottlenecks
Executing an operation in parallel involves increased resource usage (e.g. CPU or I/O). In the worst case a bottleneck situation can be the consequence and the whole system performance is impacted.
(2)High parallelism in case of DEFAULT degree and many CPUs
If a Parallel Execution is performed with DEFAULT degree, a very high parallelism is possible. In order to avoid this it is usually recommended not to use the DEFAULT degree. .
(3) Wrong CBO decisions
Activated Parallel Query can significantly impact the calculations of the Cost Based Optimizer (see note 750631). In the worst case a good (sequential) index access can turn into a long running (parallel) full table scan.
(4) Parallel DDL activates segment parallelism
If a parallel DDL operation like ALTER INDEX REBUILD PARALLEL is performed, the parallelism degree for the index remains even after the DDL operation is finished. As a consequence unintentionally parallel query might be used. In order to avoid problems you have to make sure that you reset the parallelism degree of the concerned segments to 1 after the DDL operation. The BR*TOOLS perform this activity automatically after parallelized DDL operations.
(5) Shared pool allocation
Parallel query can consume significant amounts of shared pool memory for communication purposes. Particularly in the case of high values for PARALLEL_MAX_SERVERS and PARALLEL_EXECUTION_MESSAGE_SIZE up to several GB of shared pool memory can be allocated. A consequence can be ORA-04031 errors (see note 869006).
To lists users running a parallel query and their associated slaves.
col username for a12 col "QC SID" for A6 col SID for A6 col "QC/Slave" for A10 col "Requested DOP" for 9999 col "Actual DOP" for 9999 col "slave set" for A10 set pages 100 select decode(px.qcinst_id,NULL,username, ' - '||lower(substr(s.program,length(s.program)-4,4) ) ) "Username", decode(px.qcinst_id,NULL, 'QC', '(Slave)') "QC/Slave" , to_char( px.server_set) "Slave Set", to_char(s.sid) "SID", decode(px.qcinst_id, NULL ,to_char(s.sid) ,px.qcsid) "QC SID", px.req_degree "Requested DOP", px.degree "Actual DOP" from v$px_session px, v$session s where px.sid=s.sid (+) and px.serial#=s.serial# order by 5 , 1 desc /
Query to find out the parallel execution in the system
SELECT PS.SID, DECODE(SERVER_SET, NULL, 'COORDINATOR', 1, ' CONSUMER', ' PRODUCER') ROLE, DECODE(SW.WAIT_TIME, 0, SW.EVENT, 'CPU') ACTION, SQ.SQL_TEXT FROM V$PX_SESSION PS, V$SESSION_WAIT SW, V$SQL SQ, V$SESSION S, AUDIT_ACTIONS AA WHERE PS.SID = SW.SID AND S.SID = PS.SID AND S.SQL_ADDRESS = SQ.ADDRESS (+) AND AA.ACTION = S.COMMAND ORDER BY PS.QCSID, NVL(PS.SERVER#, 0), PS.SERVER_SET;
With the following query all tables and indexes can be determined that have a parallelism degree > 1 or DEFAULT
SELECT
TABLE_NAME SEGMENT_NAME,
DEGREE,
INSTANCES
FROM DBA_TABLES
WHERE
(DEGREE != ' 1' OR INSTANCES != ' 1')
UNION
SELECT
INDEX_NAME SEGMENT_NAME,
SUBSTR(DEGREE, 1, 10) DEGREE,
SUBSTR(INSTANCES, 1, 10) INSTANCES
FROM DBA_INDEXES
WHERE
INDEX_TYPE != 'LOB' AND
(DEGREE != '1' OR INSTANCES NOT IN ('0', '1'));
Enabling Parallelism at the Session level
You can enable the different types of parallelism on session level using: ALTER SESSION ENABLE PARALLEL QUERY; ALTER SESSION ENABLE PARALLEL DDL; ALTER SESSION ENABLE PARALLEL DML; While PARALLEL QUERY and PARALLEL DDL are activated per default, PARALLEL DML has to be activated explicitly if required. Additionally it is also possible to force parallelism on session level even if no PARALLEL hint or segment parallelism is used: ALTER SESSION FORCE PARALLEL QUERY PARALLEL <degree>; ALTER SESSION FORCE PARALLEL DDL PARALLEL <degree>; ALTER SESSION FORCE PARALLEL DML PARALLEL <degree>;
Also Reads
Parallel Processing Data dictionary views and queries
https://docs.oracle.com/cd/E11882_01/server.112/e25523/parallel002.htm