sed command is a powerful Linux command and it is useful in many cases while dealing with data, and inputs in the Unix operating system. In this post, we will be looking at the sed command in the Unix example, the sed replace command, how to delete with sed command and other few cases.
Introduction to sed command in Unix/Linux
- sed – Stream Editor – works as a filter processing input line by line.
- Sed reads one line at a time, chops off the terminating newline, puts what is left into the pattern space (buffer) where the sed script can process it (often using regular expressions), then if there is anything to print – sed appends a newline and prints out the result (usually to stdout).
- Therefore, changes are not made to the edit file itself, instead, the input file, along with any changes, is written to standard output.
- If you want to make the changes from sed permanent, they must be redirected from standard output to a file. “sed -f scriptfile editfile >outputfile”
- sed goes through the file one line at a time, so if no specific address is provided for a command, it operates on all lines.
How Unix sed command work ( what are the basics of sed)
sed commands have the general form
[address[, address]][!]command [arguments]
(1) The sed utility works by sequentially reading a file, line by line, into memory. sed copies each input line into a pattern space
(2) It then performs all actions specified for the line and places the line back in memory to dump to the terminal with the requested changes made. After all, actions have taken place to this one line
-If the address of the command matches the line in the pattern space, the command is applied to that line
-If the command has no address, it is applied to each line as it enters pattern space
-If a command changes the line in pattern space, subsequent commands operate on the modified line
-An address can be either a line number or a pattern, enclosed in slashes ( /pattern/ )
-A pattern is described using regular expressions
-Additionally, a NEWLINE can be specified using the “\n” character pair
-If no pattern is specified, the command will be applied to all lines of the input file
(3) it reads the next line of the file and repeats the process until it is finished with the file.
(4) When all commands have been read, the line in pattern space is written to standard output and a new line is read into pattern space
The output can be redirected to another file to save the changes; second, the original file, by default, is left unchanged. The default is for sed to read the entire file and make changes to each line within it. It can, however, be restricted to specified lines as needed.
What is the difference between awk and sed?
The sed command is designed to edit lines of an input stream. The awk command is used to select lines out of an input stream and do some kind of processing on those lines. There is an overlap between these commands, either one can do many functions, but one usually lends itself better to your solution. The sed command works best when you merely want to make frequent modifications to many lines in the input. On the other hand, awk works best if you will be rearranging the order of the input lines or the information on the lines (e.g. swapping columns)
How address is given in the sed command in Unix/Linux?
Addresses in sed are given in the following forms
(1) Line number: This is the line number of the files
sed '1,2d': This delete the lines 1 and 2

(2) /regexp/: This is a regular expression which is checked on each line
Regular expression description
/./ Will match any line that contains at least one character
/../ Will match any line that contains at least two characters
/^#/ Will match any line that begins with a '#'
/^$/ Will match all blank lines
/[abc]/ Will match any line that contains a lowercase 'a', 'b', or 'c'
/^[abc]/ Will match any line that begins with an 'a', 'b', or 'c'
Whole line-oriented functions:
DELETE d
APPEND a
CHANGE c
SUBSTITUTE s
INSERT i
9 Line-oriented Patterns(delete, insert, append and change) sed command in Unix example
DELETE:
[address1][,address2]d
delete the addressed line(s) from the pattern space; line(s) not passed to standard output. Delete Examples:(1) d deletes the current line
(2) 8d deletes line 8
(3) /^$/d deletes all blank lines
(4) 1,100d deletes lines 1 through 100
(5) 1,/^$/d deletes from line 1 through the first blank line
(6) /^$/,/$/d deletes from the first blank line through the last line of the file
(7) /^$/,10d deletes from the first blank line through line 10
(8) /^go*t/,/[0-9]$/d deletes from the first line that begins with got, goot, gooot, etc through
the first line that ends with a digit
Here are some sed commands in Unix example
(1) Suppose we wanted to delete 8 lines starting from the first line to 8 lines in the file, the application of sed would be to delete the first 8 lines of stdin and echo the rest to stdout:
sed -e '1,8d' trace.log
(2) Commands in sed programs are separated by new lines. So Suppose if we wanted to delete lines 1 to 3 and 5 to 14, in the file, then we could use
sed -e '1,2d
5,15d'
Another possibility is to use the -e option more than once:
sed -e '1,2d' -e '5,15d'
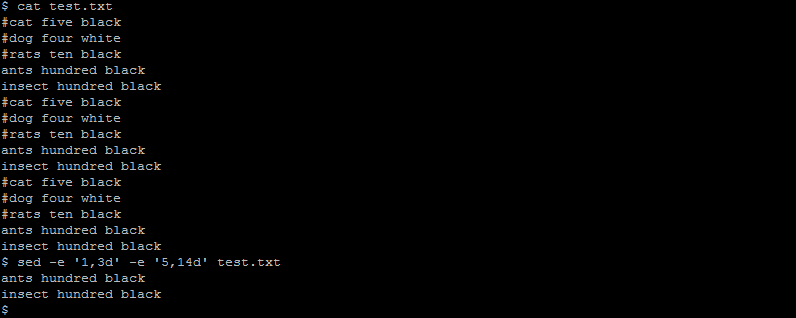
File test.txt contains 15 lines, we deleted all lines except 4 and 15
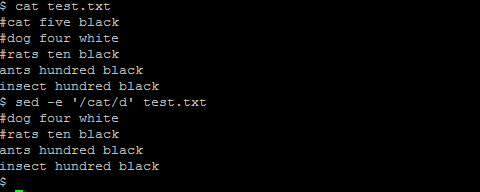
(3) Suppose we wanted to delete all the lines which contain the word cat, then we can use sed like this
sed -e '/cat/d' test.txt
(4) If you don’t want to print each line by default, you can give sed the -n option. Then only lines that you print explicitly (with the “p” action) appear on stdout.
Another way to get only the first 10 lines is to use the -n option:
sed -n -e '1,10p'
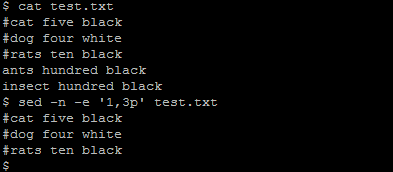
(5) Delete lines with the word IAS, but we only want lines that contain “ORA”. The traditional way to handle this would be:
grep ‘ORA’ < log | grep -v IAS
Note that this spawns two grep processes. The sed equivalent would be:
sed -n -e '/IAS/d' -e '/ORA/p'
Here -n option inhibits printing, the first pattern deletes all the lines with /debug/, and the second command forces printing of some of the remaining lines (which match /foo/)
Append, insert, and change line sed command in Unix examples:
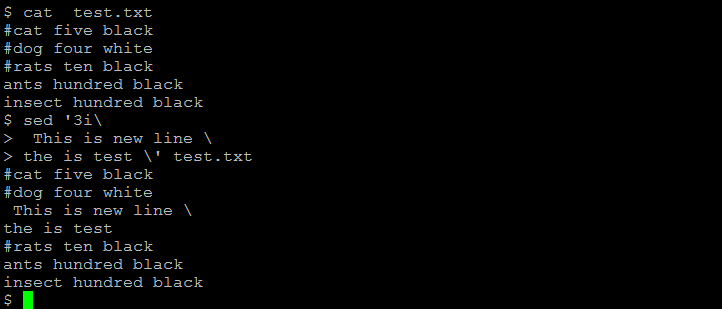
(6) To insert, we use option i
The given line will be inserted before the third line
sed '3i\
This is new line \
the is test \' test.txt
This line will be inserted before each line where GEMS is present
sed '/GEMS/ i\
Add this line after every line with GEMS’
(7) The append command works similarly but will insert a line or lines after the current line in the pattern space. It’s used as follows:
To append, we use option a
sed '3a\
This is new line\
the sed' test.txt
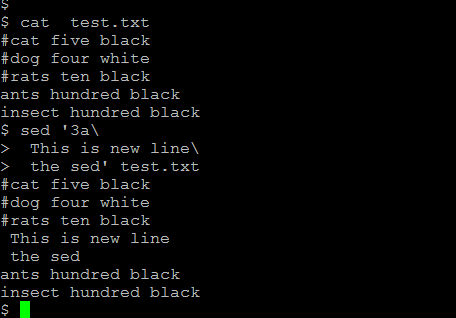
Here the text ” this is new line the sed’ is appended at the end of line 3
This example will add a line after every line with “GEMS:”
sed ‘/GEMS/ a\
Add this line after every line with GEMS’
(8) Change a line with ‘c’:
You can change the current line with a new line.
sed '/GEMS/ c\
Replace the current line with the line
The above command will replace all lines having GEMS with the new line
(9) Reading in a file with the ‘r’ command:
sed '/INCLUDE/ r filename' test.txt
Above will insert a filename after the line with the word “INCLUDE”
17 sed substitute “s” Command line Practical Examples:
Syntax: [address(es)]s/pattern/replacement/[flags] pattern - search pattern
replacement - replacement string for pattern
flags - optionally any of the following n a number from 1 to 512 indicating which occurrence of pattern should be replaced
g global, replace all occurrences of pattern in pattern space
p print contents of pattern space
w file write the contents of pattern space to file Character Description
^ Matches the beginning of the line
$ Matches the end of the line
. Matches any single character
* Will match zero or more occurrences of the previous character
[ ] Matches all the characters inside the [ ] Regular expression description
/./ Will match any line that contains at least one character
/../ Will match any line that contains at least two characters
/^#/ Will match any line that begins with a '#'
/^$/ Will match all blank lines
/[abc]/ Will match any line that contains a lowercase 'a', 'b', or 'c'
/^[abc]/ Will match any line that begins with an 'a', 'b', or 'c'
Here are sed replace command examples
(1) Substitute mat for the first occurrence of cat in pattern space
s/cat/mat/

(2)Substitutes Dick for the second occurrence of Tom in the pattern space
s/Tom/Dick/2
(3) Substitutes plastic for the first occurrence of wood and outputs (prints) pattern space
s/wood/plastic/p
(4) Substitutes Dr for every occurrence of Mr in pattern space
s/Mr/Dr/g
(5) if you want to add space at the start of each line

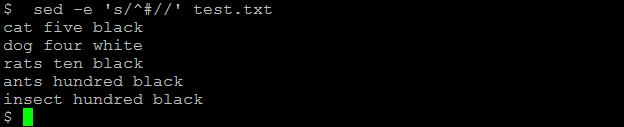
(6) it removes commented lines from the file
sed -e ‘s/#.*//’ test.txt

If you just want to remove the comment from the fine
(7) replaces only 1st instance in a line
sed ‘s/foo/bar/’
(8) replaces only 4th instance in a line
sed ‘s/foot/feet/4’
(9) replaces ALL instances in a line
sed ‘s/foot/feet/g’
(10) substitute “foo” with “bar” EXCEPT for lines which contain “bat” here ! is used to negate the presence of bat
sed ‘/bat/!s/foo/bar/g’
(11) change “scarlet” or “ruby” or “puce” to “red”. This is multiple substitution command
sed ‘s/scarlet/red/g;s/ruby/red/g;s/puce/red/g’
Related: Find command
(12) This substitute the first occurrence of A to a from lines 101 to the end lines
sed ‘101,$ s/A/a/’
(13) it will remove commented line from the beginning of the file until it finds the keyword “start”
sed -e ‘1,/start/ s/#.*//’
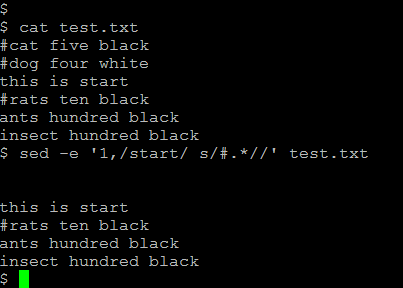
(14) it will remove comments everywhere except the lines between the two keywords
sed -e '1,/start/ s/#.*//' -e '/stop/,$ s/#.*//'
(15) it will swap ‘hills’ for ‘mountains’, but only on blocks of text beginning with a blank line, and ending with a line beginning with the three characters ‘END’, inclusive.
sed -e '/^$/,/^END/s/hills/mountains/g' myfile3.txt
(16) it will match a phrase beginning with ‘<‘ and ending with ‘>’, and containing any number of characters in between. This phrase will be deleted (replaced with an empty string)
sed -e ‘s/<.*>//g’ myfile.html
(17) To remove all alpha-numeric characters present in every line
sed ‘s/[a-zA-Z0-9]//g’ filename
How to apply Multiple commands for one address using sed
Braces { } can be used to apply multiple commands to an address:
[/pattern/[,/pattern/]]{
command1
command2
command3
}
Practical Examples for Multiple commands in sed
(1) The below example will apply four substitution commands to lines 10 through 25, inclusive
10,25{
s/[Ll]amp/Bulb\/Lamp/g
s/good/bad/g
s/cat/TOPM/gs/gat/TOPM/g
}
Related : Useful Unix command for DBA
(2) You can also use regular expression addresses or a combination of the two:
1,/^END/{
s/[Ll]inux/GNU\/Linux/g
s/samba/Samba/g
s/posix/POSIX/g
p
}
This example will apply all the commands between ‘{ }’ to the lines starting at 1 and up to a line beginning with the letters
“END”, or the end of the file if “END” is not found in the source file.
How to use unix sed command as script
sed -f scriptname
If you have a large number of sed commands, you can put then into a file and use
sed -f sedscript <old >newwhere sedscript could look like this:
# sed comment – This script changes lower case vowels to upper case
s/a/A/g
s/e/E/g
s/i/I/g
s/o/O/g
s/u/U/g
Some more sed command in Unix example
(1) To remove the first letter in all the lines in the file
sed 's/^.//' filename
(2) To remove the last letter in all the lines in the file
sed 's/.$//' test.txt
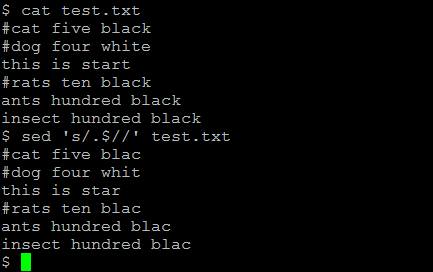
(3) To remove all digits present in every line of a file:
sed 's/[0-9]//g' file
(4) sed ‘/start/,/stop/ s/#.*//’ # The first pattern turns on a flag that tells sed to perform the substitute command on every line. The second pattern turns off the flag. If the “start” and “stop” pattern occurs twice, the substitution is done both times. If the “stop” pattern is missing, the flag is never turned off, and the substitution will be performed on every line until the end of the file.
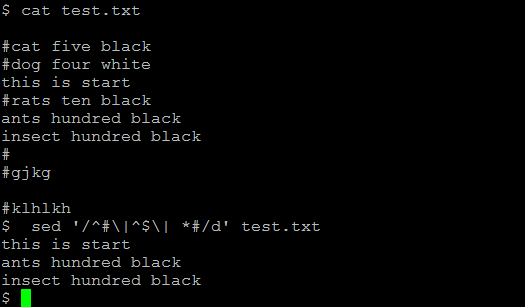
5) To remove empty lines or those beginning with #
sed '/^#\|^$\| *#/d' test.txt
Here (^#) indicates the beginning of a line
(^$) represents blank lines.
The vertical bars indicate Boolean operations, whereas the backward slash is used to escape the vertical bars.
Most of the content above given is valid for Linux/Solaris/AIX. So AIX sed command/Linux sed command will also work the same way. Hope you like this post on the sed command in Unix example
Related Articles
Linux command for Oracle DBA: This page has useful Unix command for Oracle DBA to help you in your day-to-day activities. Some are applicable to Linux also. How to kill the process
how to copy directory in Linux: Check out this post for a detailed description of how to copy a file/directory in Linux. Examples of copy directory Linux command are also given
grep command: Grep command Means – globally search regular expression. grep command in Unix is used for searching text, regular expression across multiple files
Linux Tutorials
find command
basic Unix commands pdf