What is Oracle index clustering factor(CF)?
The clustering factor is a number that represents the degree to which data is randomly distributed in a table as compared to the indexed column. In simple terms, it is the number of “block switches” while reading a table using an index.
It is an important statistic that play important role in optimizer calculation. It is used to weight the calculation for the index range scans. When the clustering factor is higher, the cost of index range scan is higher
A good Clustering factor is equal (or near) to the values of the number of blocks of the table.
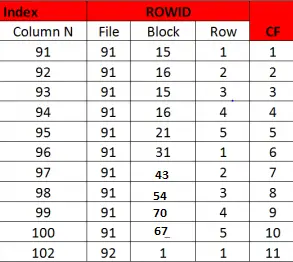
A bad Clustering factor is equal (or near) to the number of rows of the table.
How is CF calculated?
Oracle calculates the clustering factor by doing a full scan of the index walking the leaf blocks from end to end. For each entry in each leaf, Oracle checks the absolute file number and the block id, as obtained from the indexed value’s ROWID. It keeps a running count of how many “different” blocks contain data rows pointed to by the index. The block address from the first entry is compared to the block address from the second entry. If it is the same table block, Oracle does not increment the counter. If the table blocks are different, Oracle adds one to the count. This counting process continues from entry to entry always comparing the previous entry to the current one.
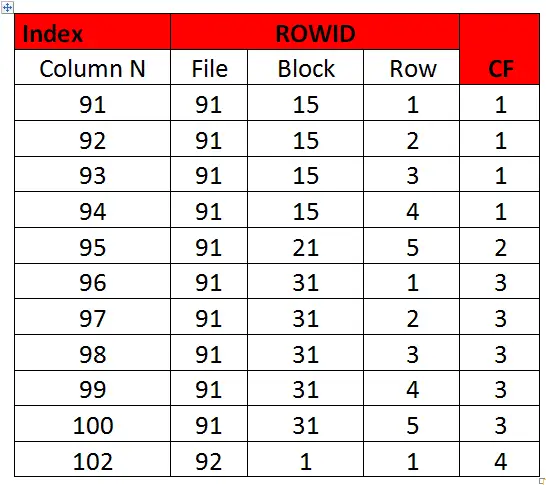
The above is a good CF example as CF is equal to the number of blocks
Example of Bad Clustering factor
Here the clustering factor is equal to no of rows
This method of counting has its own unexpected outcome. Suppose the data happens to be populated over a small set of blocks, but not in order in reference to the index key, then a set of rows could appear to be over a large set of blocks when maybe there are only a few true distinct blocks. So CF would be higher but in fact, it is touching very few blocks. This problem can be mitigated in 12c by using table preferences and specifying the tabled cached block.
how to improve clustering factor in oracle
An index rebuild would not have any effect on the clustering factor. The table needs to be sorted and rebuild in order to lower the clustering factor.
Query to determine the clustering factor
CF is stored in the data dictionary and can be viewed from dba_indexes (or user_indexes).
In fact, all the index statistics can be found there
SELECT index_name, index_type, uniqueness, blevel, leaf_blocks, distinct_keys, avg_leaf_blocks_per_key,
avg_data_blocks_per_key, clustering_factor, num_rows, sample_size, last_analyzed, partitioned
FROM dba_indexes
WHERE table_name = 'ORDERS' ;
How Oracle index clustering factor impact the optimizer plan?
The clustering factor is the primary statistic the optimizer uses to weight index access paths. It is an estimate of the number of LIOs to table blocks required to acquire all the rows that satisfy the query in order. The higher the clustering factor, the more LIOs the optimizer will estimate will be required. The more LIOs that are required, the less attractive, and thus more costly, the use of the index will be.
Related Article
Oracle partition index : Understanding Oracle partition index, What is Global Nonpartitioned Indexes?, What is local prefixed indexes, nonprefixed local index
find indexes on a table in oracle : check out this article to find queries on how to find indexes on a table in oracle, list all indexes in the schema, index status, index column
types of indexes in oracle : This page consists of oracle indexes information, different types of indexes in oracle with an example, how to create/drop/alter the index in oracle
Virtual Index in Oracle : What is Virtual Index in Oracle? Uses, limitation, advantage and how to use to check explain plan in Oracle database, Hidden parameter _USE_NOSEGMENT_INDEXES
Excellent….
Thanks
nice *post