We will be discussing Oracle indexes, types of indexes in oracle with example, and how to create index in oracle in this post. I will through light on all the options on how to create an index in oracle. I hope you will like this post. I will be looking forward to feedback on this post
What are Oracle Indexes?
- Just like we have an index present in the textbooks to help us find the particular topic in the book, the Oracle index behaves the same way. we have different types of indexes in oracle.
- Indexes are used to search the rows in the oracle table quickly. If the index is not present the select query has to read the whole table and returns the rows. With Index, the rows can be retrieved quickly
- We should create Indexes when retrieving a small number of rows from a table. or to retrieve the first set of rows as fast as possible from some query that will ultimately return a large number of rows. It also depends on the data distribution i.e clustering factor
- Indexes are logically and physically independent of the data in the associate table.
- Indexes are optional structures associated with tables and clusters. You can create indexes on one or more columns of a table to speed SQL statement execution on that table.
- Indexes are the primary means of reducing disk I/O when properly used.
- The query decides at the beginning whether to use an index or not
- The best thing with indexes is that the retrieval performance of indexed data remains almost constant, even as new rows are inserted. However, the presence of many indexes on a table decreases the performance of updates, deletes, and inserts because Oracle must also update the indexes associated with the table.
- If you are the owner of the table, you can create an index or if you want to create index for a table in another schema then you should either have CREATE ANY INDEX system privilege or index privilege on that table
Logical Type of Indexes
It defines the application characteristics of the Index
| Unique or Non-Unique | An index can be Unique or non Unique. Oracle creates a unique index for Primary key and unique key constraints If non-unique indexes are already present on that column, it will not create a new unique index for the Primary key in Oracle |
| Composite | The index can be comprised of single or multiple columns. Composite indexes can speed the retrieval of data for SELECT statements in which the WHERE clause references all or the leading portion of the columns in the composite index. |
| Function-Based indexes | The indexed column’s data is based on a calculation |
| Application Domain Indexes | This index is used in special applications (Spatial, Text).
|
What is ROWID Pseudo column
ROWID returns the address of each row in the table. Oracle assigns a ROWID to each row.ROWID consists of following
- The data object number of the object
- The data block in the datafile in which the row resides
- The position of the row in the data block (the first row is 0)
- The data file in which the row resides (the first file is 1). The file number is relative to the tablespace.
Oracle uses ROWID internally to access rows. For instance, Oracle stores ROWID in the index and use it to access the row in the table.
You can display the ROWID of rows using the SELECT command as follows:
select rowid, emp_name from emp;
ROWID EMP_NAME
---------- ----------------
AAADC576474722aSAAA John
Oracle provides a package called DBMS_ROWID to decode ROWID.
Once a row is assigned a ROWID Oracle does not change ROWID during the lifetime of the row. But it changes when the table is rebuilt When rows are moved across the partition, or shrinking of the table
Types of indexes in oracle with example
There are 6 different types of indexes in oracle
(1) B-Tree
(2) Compressed B-Tree
(3) Bitmap
(4) Function-Based
(5) Reverse Key (RKI)
(6) Index organized table (IOT).
Let’s find out each of them in detail and how to create an index in oracle for each of these types
B – Tree Index:
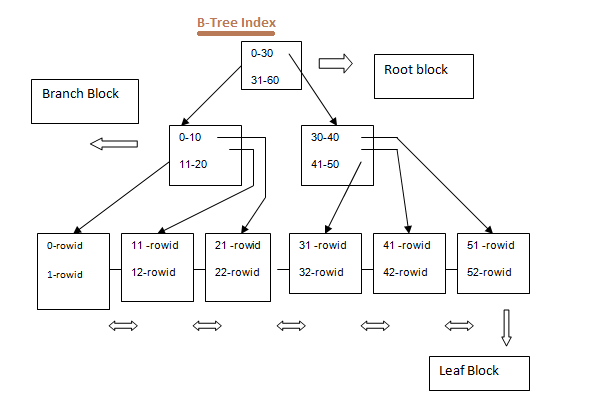
- B-Tree Indexes (balanced tree) are the most common type of index.
- B-Tree index stored the ROWID and the index key value in a tree structure.
- When creating an index, a ROOT block is created, then BRANCH blocks are created and finally LEAF blocks.
- Each branch holds the range of data its leaf blocks hold, and each root holds the range of data its branches hold:
- B-Tree indexes are most useful on columns that appear in the where clause (SELECT … WHERE EMPNO=1).
- The Oracle server, keeps the tree balanced by splitting index blocks when new data is inserted into the table.
- Whenever a DML statement is performed on the index’s table, index activity occurs, making the index to grow (add leaf and branches).
Advantages
- All leaf blocks of the tree are at the same depth.
- B-tree indexes automatically stay balanced.
- All blocks of the B-tree are three-quarters full on average.
- B-trees provide excellent retrieval performance for a wide range of queries, including exact match and range searches.
- Inserts, updates, and deletes are efficient, maintaining key order for fast retrieval.
- B-tree performance is good for both small and large tables and does not degrade as the size of a table grows.
Create B-Tree Index Syntax with examples
CREATE <UNIQUE|NON UNIQUE> INDEX <index_name> ON <table_name> (<column_name>,<column_name>…) TABLESPACE <tablespace_name>; Example Create index scott.exp_idx on table scott.example(name) Tablespace TOOLS;
What are compressed B-tree Indexes
- Compressed B-Tree Indexes are built on large tables, in a data warehouse environment. In this type of index, duplicate occurrences of the same value are eliminated, thus reducing the amount of storage space, the index requires.
- In a compressed B-Tree index, for each key value, a list of ROWIDs is kept
- Specifying the COMPRESS keyword when creating an index (CREATE INDEX … COMPRESS) will create a compressed B-Tree index.
- A regular B-Tree index can be rebuilt using the COMPRESS keyword to compress it.
Create Compressed B-Tree Index Syntax with examples
CREATE <UNIQUE|NON UNIQUE> INDEX <index_name> ON <table_name> (<column_name>,<column_name>…) PCTFREE <integer> TABLESPACE <tablespace_name> Compress <column number>
What are Bitmap Indexes
- Bitmap Indexes are most appropriate on low distinct cardinality data (as opposed to B-Tree indexes).
- This type of index creates a binary map of all index values, and stores that map in the index blocks, this means that the index will require less space than the B-Tree index.
- Each bit in the bitmap corresponds to a possible rowid. If the bit is set, then it means that the row with the corresponding rowid contains the key value. A mapping function converts the bit position to an actual rowid, so the bitmap index provides the same functionality as a regular index even though it uses a different representation internally. If the number of different key values is small, then bitmap indexes are very space efficient
- When there are bitmap indexes on tables then updates will take out full table locks. So, the Bitmap index is useful on large columns with low-DML(infrequent updates) activity or read-only tables. This is the reason you often find bitmap indexes are extensively used in the data warehouse environment(DWH).
- Bitmap Index structure contains a map of bits which indicate the value in the column, for example, for the GENDER column, the index block will hold the starting ROWID, the ending ROWID and the bit map:
- Bitmap indexes are very useful when created on columns with low cardinality, used with the AND & OR operator in the query condition:
Create Bitmap Index Syntax with examples
CREATE BITMAP INDEX <index_name> ON <table_name> (<column_name>,<column_name>…) PCTFREE <integer> TABLESPACE <tablespace_name>
Example
CREATE BITMAP INDEX ON emp_data(gender); SELECT COUNT(*) FROM emp_data WHERE GENDER=’M”;
Advantages Of Bitmap Indexes
- Reduced response time for large classes of queries
- A substantial reduction in space usage compared to other indexing techniques
- Dramatic performance gains even on very low-end hardware
- Very efficient parallel DML and loads
Function Based Indexes
- Function-Based Indexes are indexes created on columns that a function is usually applied on.
- When using a function on an indexed column, the index is ignored, therefore a function-based index is very useful for these operations.
Create Function based Index Syntax with examples
CREATE INDEX <index_name> ON <table_name> [ Function(<column_name>,<column_name.)] TABLESPACE <tablespace_name>; Example CREATE INDEX EMP_IDX on EMP(UPPER(ENAME)); SELECT * FROM Emp WHERE UPPER(Ename) like ‘JOHN`;
What are Reverse-Key Indexes
- They are special types of B-Tree indexes and are very useful when created on columns containing sequential numbers.
- When using a regular B-Tree, the index will grow to have many branches and perhaps several levels, thus causing performance degradation, the RKI solve the problem by reversing the bytes of each column key and indexing the new data.
- This method distributes the data evenly in the index. Creating an RKI is done using the REVERSE keyword: CREATE INDEX … ON … REVERSE;
Create Reverse key Index Syntax with examples
CREATE INDEX <index_name> ON <table_name> (<column_name>) TABLESPACE <tablespace_name> REVERSE; Example CREATE INDEX emp_idx i ON emp_table (firstname,lastname) REVERSE;
What are Index Organized Tables (IOT) –
- B-Tree, Bitmap and Reverse key indexes are used for tables that store data in an un-ordered fashion (Heap Tables).
- These indexes contain the location of the ROWID of the required table row, thus allowing direct access to row data
- An index-organized table differs from an ordinary table because the data for the table is held in its associated index. Changes to the table data, such as adding new rows, updating rows, or deleting rows, result in updating the index.
- The index-organized table is like an ordinary table with an index on one or more of its columns, but instead of maintaining two separate storage for the table and the B-tree index, the database system maintains only a single B-tree index which contains both the encoded key value and the associated column values for the corresponding row. Rather than having a row’s rowid as the second element of the index entry, the actual data row is stored in the B-tree index. The data rows are built on the primary key for the table, and each B-tree index entry contains <primary_key_value, non_primary_key_column_values>. Index-organized tables are suitable for accessing data by the primary key or any key that is a valid prefix of the primary key.
- There is no duplication of key values because only non-key column values are stored with the key. You can build secondary indexes to provide efficient access to other columns. Applications manipulate the index-organized table just like an ordinary table, using SQL statements. However, the database system performs all operations by manipulating the corresponding B-tree index.
Features of Index organized table
- The primary key uniquely identifies a row; the primary key must be specified
- Primary key-based access
- Logical rowid in ROWID pseudo column allows building secondary indexes
- UNIQUE constraints are not allowed but triggers are allowed
- Cannot be stored in a cluster
- Can contain LOB columns but not LONG columns
- Distribution and replication are not supported
CREATE TABLE command: CREATE TABLE … ORGANIZATION INDEX TABLESPACE … (specify this is an IOT) PCTTHRESHOLD … (specify % of block to hold in order to store row data, valid 0-50 (default 50)) INCLUDING … (specify which column to break a row when row length exceeds PCTTHRESHOLD) OVERFLOW TABLESPACE … (specify the tablespace where the second part of the row will be stored) MAPPING TABLE; (cause creation of a mapping table, needed when creating Bitmap index on IOT)
The Mapping Table maps the index’s physical ROWIDs to logical ROWIDs in the IOT. IOT uses logical ROWIDs to manage table access by index because physical ROWIDs are changed whenever data is added to or removed from the table. In order to distinguish the IOT from other indexes, query the USER_INDEXES view using the pct_direct_access column. Only IOT will have a non-NULL value for this column.
Application Domain Indexes
Oracle provides extensible indexing to accommodate indexes on complex data types such as documents, spatial data, images, and video clips and to make use of specialized indexing techniques.
With extensible indexing, you can encapsulate application-specific index management routines as an index type schema object and define a domain index (an application-specific index) on table columns or attributes of an object type. Extensible indexing also provides efficient processing of application-specific operators.
The application software, called the cartridge, controls the structure and content of a domain index. The Oracle server interacts with the application to build, maintain, and search the domain index. The index structure itself can be stored in the Oracle database as an index-organized table or externally as a file.
Using Domain Indexes
Domain indexes are built using the indexing logic supplied by a user-defined index type. An index type provides an efficient mechanism to access data that satisfy certain operator predicates. Typically, the user-defined index type is part of an Oracle option, like the Spatial option.
For example, the SpatialIndextype allows efficient search and retrieval of spatial data that overlap a given bounding box.
The cartridge determines the parameters you can specify in creating and maintaining the domain index. Similarly, the performance and storage characteristics of the domain index are presented in the specific cartridge documentation.
So far we have covered different types of indexes in oracle with an example, lets now check how to alter/drop/recreate them
How to recreate the Indexes/rebuild index in oracle
We can use the ALTER INDEX … REBUILD statement to reorganize or compact an existing index or to change its storage characteristics
The REBUILD statement uses the existing index as the basis for the new one.
ALTER INDEX … REBUILD is usually faster than dropping and re-creating an index.
It reads all the index blocks using multi-block I/O and then discards the branch blocks.
A further advantage of this approach is that the old index is still available for queries while the rebuild is in progress.
Alter index <index name> rebuild ; Alter index <index name> rebuild tablespace <name>;
How to Write Statements that Avoid Using Indexes
- You can use the NO_INDEX optimizer hint to give the CBO maximum flexibility while disallowing the use of a certain index.
- You can use the FULL hint to force the optimizer to choose a full table scan instead of an index scan.
- You can use the INDEX, INDEX_COMBINE, or AND_EQUAL hints to force the optimizer to use one index or a set of listed indexes instead of another.
How to gather statistics for Indexes
- Index statistics are gathered using the ANALYZE INDEX or dbms_stats statement.
- Available options are COMPUTE/ESTIMATE STATISTICS or VALIDATE STRUCTURE.
- From 10g onwards, when the index is created, compute statistics is done automatically
- When using the validate structure, Oracle populates the INDEX_STATS view with statistics related to the analyzed index.
- The statistics contain the number of leaf rows & blocks (LF_ROWS, LF_BLKS), number of branch rows & blocks (BR_ROWS, BR_BLKS), number of deleted leaf rows (DEL_LF_ROWS), used space (USED_SPACE), number of distinct keys (DISTINCT_KEYS), etc.
- These statistics can be used to determine if the index should be rebuilt or not
How does Oracle decide about the usage of the index?
- Oracle automatically decides whether the index should be used by the Optimizer engine.
- Oracle decides whether to use an index or not depending upon the query.
- Oracle can understand whether using an index will improve the performance in the given query. If Oracle thinks using an index will improve performance, it will use the index otherwise it will ignore the index.
Let us understand by this example
We have a table emp which contains emp_name, salary,dept_no ,emp_no,date_of_joining and we have an index on emp_name
Query 1
select * from emp where emp_name = 'John';
The above query will use the index as we are trying to get information about an emp based on the name.
Query 2
select * from emp;
The above query will not use the index as we are trying to find all the rows in the table and we don’t have a where clause in the query
Query 3
select * from emp where dept_no =5;
The above query will not use the index as the where clause does not select the column which has an index
Query 4
select * from emp where substr(emp_name,1,4) =’XYZW’;
The above query will not use the index as the where clause uses the function on the column and we don’t have a functional index on emp_name
How to create or rebuild the index Online?
Oracle used to lock the table on which index is being created throughout the creation process in older versions. This makes the table unavailable for data manipulation during the creation of the index.
Now with 8i, Oracle introduced online rebuilding of the index where Oracle doesn’t lock the table on which index is being built.
Online indexing is provided through the keyword ONLINE.
CREATE <UNIQUE|NON UNIQUE> INDEX <index_name> ON <table_name> (<column_name>,<column_name>…) PCTFREE <integer> TABLESPACE <tablespace_name> Online; Alter index <index name> rebuild online;
Basically, with an online rebuild, Oracle locks the table at the start and end of the creation of the index. It allows transactions in between. The mechanism has been quite improved with 11g and 12c
What are the Drawbacks of the Indexes
- Indexes increase the performance of a select query, but they can also decrease the performance of data manipulation.
- Many indexes on a table can slow down INSERTS and DELETES drastically
- The more the indexes on the table, the more time inserts and deleting will take.
- Similarly, every change to an indexed column will need a change to the index.
- So we need to choose the index very carefully and drop which are not in use.
- Though the extra space occupied by indexes is also a consideration, it may not matter much since the cost of data storage has declined substantially.
What are Unusable indexes?
- An unusable index is ignored by the optimizer in deciding the explain plan
- It is also not maintained by DML i.e update, insert, delete does the update the index
- There could be several reasons for the index being in an unusable state. If you did the rebuild of the table but did not rebuild the index, then the index will be in an unusable state. One other reason to make an index unusable is to improve bulk load performance. Another reason might be optimizer picks up the wrong index every time and time is critical so you may decide to make it unusable
- An unusable index or index partition must be rebuilt, or dropped and re-created before it can be used. Truncating a table makes an unusable index valid
- Beginning with Oracle Database 11g Release 2, when you make an existing index unusable, its index segment is dropped.
- The functionality of unusable indexes depends on the setting of the SKIP_UNUSABLE_INDEXES initialization parameter.
When SKIP_UNUSABLE_INDEXES is TRUE (the default), then:
- DML statements against the table proceed, but unusable indexes are not maintained.
- DML statements terminate with an error if there are any unusable indexes that are used to enforce the UNIQUE constraint.
- For nonpartitioned indexes, the optimizer does not consider any unusable indexes when creating an access plan for SELECT statements. The only exception is when an index is explicitly specified with the INDEX() hint.
When SKIP_UNUSABLE_INDEXES is FALSE, then:
- If any unusable indexes or index partitions are present, any DML statements that would cause those indexes or index partitions to be updated are terminated with an error.
- For SELECT statements, if an unusable index or unusable index partition is present but the optimizer does not choose to use it for the access plan, the statement proceeds. However, if the optimizer does choose to use the unusable index or unusable index partition, the statement terminates with an error.
Data dictionary views on Indexes
| DBA_INDEXES ALL_INDEXES USER_INDEXES | DBA view describes indexes on all tables in the database. ALL view describes indexes on all tables accessible to the user. USER view is restricted to indexes owned by the user. Some columns in these views contain statistics that are generated by the DBMS_STATS package or ANALYZE statement. |
| DBA_IND_COLUMNS ALL_IND_COLUMNS USER_IND_COLUMNS | These views describe the columns of indexes on tables. Some columns in these views contain statistics that are generated by the DBMS_STATS package or ANALYZE statement. |
| DBA_IND_EXPRESSIONS ALL_IND_EXPRESSIONS USER_IND_EXPRESSIONS | These views describe the expressions of function-based indexes on tables. |
| DBA_IND_STATISTICS ALL_IND_STATISTICS USER_IND_STATISTICS | These views contain optimizer statistics for indexes. |
how to find indexes on a table
set pagesize 50000 verify off echo off
col table_name head 'Table Name' format a20
col index_name head 'Index Name' format a25
col column_name head 'Column Name' format a30
break on table_name on index_name
select table_name, index_name, column_name
from all_ind_columns
where table_name like upper('&Table_Name')
order by table_name, index_name, column_position
/
How to determine index size
Size of INDEX select segment_name,sum(bytes)/1024/1024/1024 as "SIZE in GB" from user_segments where segment_name='INDEX_NAME' group by segment_name; OR select owner,segment_name,sum(bytes)/1024/1024/1024 as "SIZE in GB" from dba_segments where owner='SCHEMA_NAME' and segment_name='INDEX_NAME' group by owner,segment_name; List of Size of all INDEXES of a USER select segment_name,sum(bytes)/1024/1024/1024 as "SIZE in GB" from user_segments where segment_type='INDEX' group by segment_name order by "SIZE in GB" desc; OR select owner,segment_name,sum(bytes)/1024/1024/1024 as "SIZE in GB" from dba_segments where owner='SCHEMA_NAME' and segment_type='INDEX' group by owner,segment_name order by "SIZE in GB" desc; Sum of sizes of all indexes select owner,sum(bytes)/1024/1024/1024 as "SIZE in GB" from dba_segments where owner='SCHEMA_NAME' and segment_type='INDEX' group by owner;
How to determine the Index definition
set long 4000
select dbms_metadata.get_ddl('INDEX','<INDEX Name>','<INDEX OWNER') from dual;
How to determine the Index statistics
set pages 250
set linesize 100
set verify off
col table_name format a24 heading 'TABLE NAME'
col index_name format a23 heading 'INDEX NAME'
col u format a1 heading 'U'
col blevel format 0 heading 'BL'
col leaf_blocks format 999990 heading 'LEAF|BLOCKS'
col distinct_keys format 9999990 heading 'DISTINCT|KEYS'
col avg_leaf_blocks_per_key format 9999990 heading 'LEAF|BLKS|/KEY'
col avg_data_blocks_per_key format 9999990 heading 'DATA|BLKS|/KEY'
rem
break on table_name
rem
select table_name, index_name,
decode( uniqueness, 'UNIQUE', 'U', null ) u,
blevel, leaf_blocks, distinct_keys,
avg_leaf_blocks_per_key, avg_data_blocks_per_key
from sys.dba_indexes
where table_owner like upper('&owner')
and table_name like upper('&table')
order by table_owner, table_name, index_name;
Hope you like this post on oracle index, types of indexes in oracle with example and how to create an index in Oracle.
Related Articles
external tables in Oracle : Check out this post for information on the usage of the external tables in oracle with an example, how to create an external table, how to use it
Oracle Create table : Tables are the basic unit of data storage in an Oracle Database. we cover how to use Oracle create table command to create a table with a foreign key /primary key
oracle create tablespace statement: This article on how to create tablespace in oracle, various characteristics associated with it and different create tablespace statements
Find indexes status and assigned columns for a table
Virtual Index in Oracle: What is Virtual Index in Oracle? Uses, limitations, advantages and how to use to check to explain plan in Oracle database, Hidden parameter _USE_NOSEGMENT_INDEXES
Oracle Index clustering factor: How Oracle Index clustering factor is calculated and how it impacts the explain plan
Oracle Partition Index : Understanding Oracle partition index, What is Global Non-partitioned Indexes?, What is local prefixed indexes, non-prefixed local index
Recommended Courses
Here is the nice Udemy Course for Oracle SQL
Oracle-Sql-Step-by-step : This course covers basic sql, joins, Creating Tables and modifying its structure, Create View, Union, Union -all and much other stuff. A great course and must-have course for SQL starter
The Complete Oracle SQL Certification Course : This is a good course for anybody who wants to be Job ready for SQL developer skills. A nice explained course
Oracle SQL Developer: Essentials, Tips and Tricks : Oracle Sql developer tool is being used by many developers. This course gives us tricks and lessons on how to effectively use it and become a productive sql developer
Oracle SQL Performance Tuning Masterclass 2020 : Performance tuning is one of the critical and most sought skills. This is a good course to learn about it and start doing sql performance tuning
see https://www.reddit.com/r/oracle/comments/4a4k12/a_complete_resource_on_oracle_indexes/d0xdgiu to find out why you probably don’t want to read this…..
See my reply on https://www.reddit.com/r/oracle/comments/4a4k12/a_complete_resource_on_oracle_indexes/d0y3vyj
how will you identify unused indexes for dropping them
You can enable monitoring on the indexes
ALTER INDEX index_name MONITORING USAGE;
and then check the usage from 2-3 days in the view
v$object_usage and then decide if the index need to be dropped
We can disable monitoring using the below command
ALTER INDEX index_name NOMONITORING USAGE;
Pingback: Oracle – Indexes | Sathiyan