This is part of the Oracle SQL tutorial and has good examples and explanations on Regexp in Oracle.
regexp in oracle
- String manipulation and searching contribute to a large percentage of the logic within a Web-based application.
- Regular expressions are a method of describing both simple and complex
- patterns for searching and manipulating.
- Usage ranges from the simple (“Find the word SAN in the text”) to the more complex (“Extract all URLs from the text”) to the archaic (“Find all words in which every second character is a vowel”).
- From Oracle Database 10g, you can use both SQL and PL/SQL to implement regular expression support.
- The National Language Support Run Time Library (NLSRTL) provides all of the linguistic elements used to implement regular expression support.
The following functions have been introduced
REGEXP_LIKE: Similar to the LIKE operator, but performs regular expression matching
instead of simple pattern-matching
REGEXP_REPLACE: Searches for a regular expression pattern and replaces it with a
replacement string
REGEXP_INSTR: Searches for a given string for a regular expression pattern and returns
the position where the match is found
REGEXP_SUBSTR: Searches for a regular expression pattern within a given string and
returns the matched sub-string
SELECT first_name, last_name, salary, TO_CHAR(hire_date, 'yyyy') FROM emp WHERE REGEXP_LIKE( TO_CHAR(hire_date, 'yyyy'), '^201[1-4]$');
This example illustrates the use of the REGEXP_LIKE functions to display employee names and salaries for employees hired between 2011 and 2014. The example uses the ‘^’ to indicate that the beginning of the line has to be 201, and [ – ] with ‘$’ to specify a range of valid characters as the very last character.
Integrity Constraints using regexp in oracle
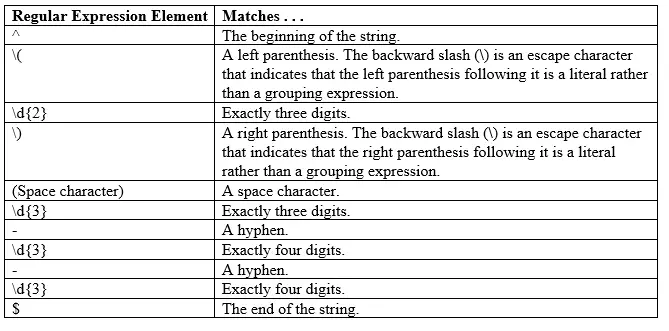
Regular expressions are a useful way to enforce integrity constraints. For example, suppose that you want to ensure that phone numbers are entered into the database in a standard format. Let’s create a emp_contact table and add a check constraint to the phone_number column to enforce the following format mask
(AA) AAA-AAA-AAA
CREATE TABLE emp_contact
(
emp_name VARCHAR2(30),
phone_number VARCHAR2(30)
CONSTRAINT phone_number_format
CHECK ( REGEXP_LIKE ( p_number, '^(\d{2}) \d{3}-\d{3}-\d{3}$' ) )
);
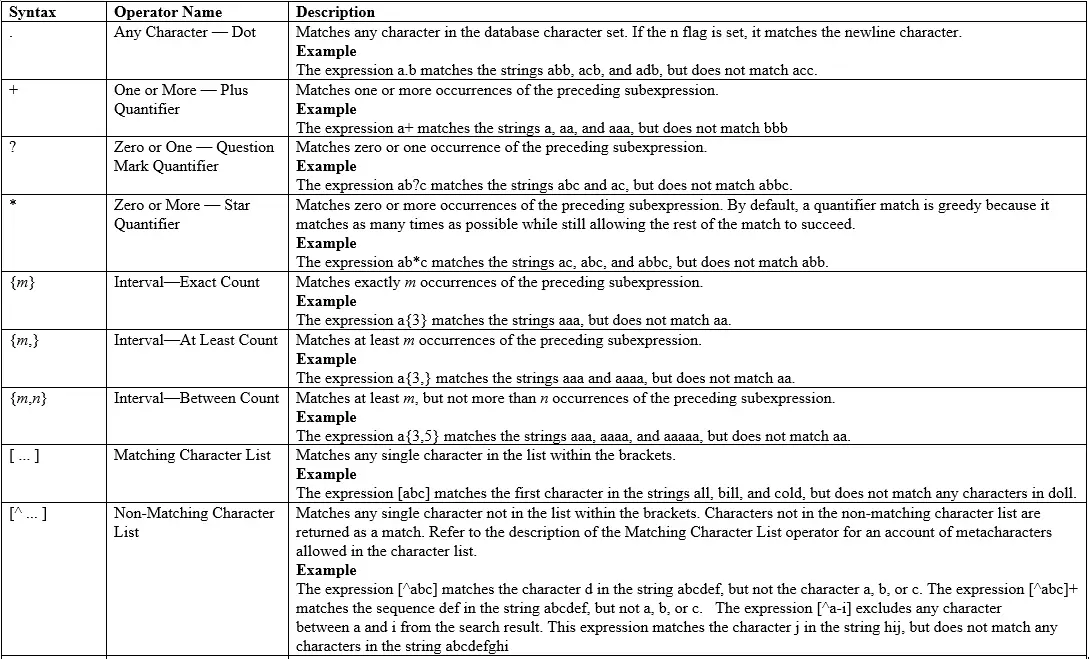
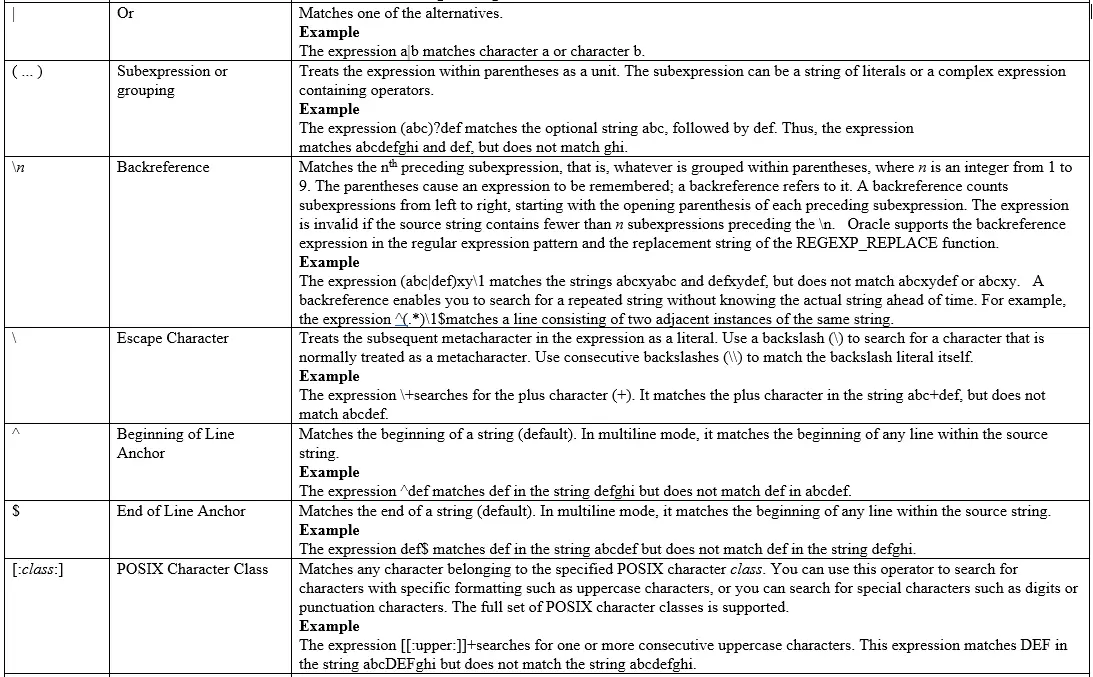
Regular expression meta character in Oracle Database

Hope you like this post on regexp in oracle
Related Articles
Oracle PLSQL Tables
Date functions in Oracle
Oracle decode
Oracle Case Statement
Group by Oracle
https://docs.oracle.com/cd/B19306_01/B14251_01/adfns_regexp.htm
