
In this article I will talk about Oracle RAC (Oracle Real application clusters)
ORACLE RAC CONCEPTS AND FUNCTIONAL OVERVIEW
- RAC is the ability to have two or more instances connect to the same database. These instances reside on separate servers, thereby allowing each instance to make full use of the processing ability of each server. As these instances are accessing the same database they need to be able to communicate with each other, this is done through physical interconnects that join the servers together. All the servers in the configuration make up the cluster.
- All instances in a cluster share access to common database resources, this access needs to be coordinated between the instances in order to maintain the overall integrity of the database. In order to coordinate this access RAC databases have a Global Resource Directory. This Global Resource Directory is RAC specific and is not required on single instance systems.
Global Resource Directory(GRD)
- Global Resource Directory provides an extra layer of control in order to allow all instances in a cluster to share access to shared database resources. The Global Resource Directory resides in the SGA of each instance in the cluster, with each instance maintaining its own portion. The main role of the Global Resource Directory is to ensure that access and changes to common resources is controlled between the instances in order to maintain the integrity of the database.
- Global Enqueue Service(GES) and the Global Cache Service(GCS) maintain the information in the Global Resource Directory. Although the Global Resource Directory is split amongst all instances in the cluster, the Global Cache Service(GCS) and Global Enqueue Service(GES) nominate one instance to manage all information about a particular database resource. This instance is called the resource master. This ownership is periodically checked and changed accordingly between instances, this is done to reduce interconnect traffic and resource acquisition time.
Global Cache Service(GCS)
Global Cache Service is responsible for cache fusion i.e. transmitting data blocks between the instances. The main features of this processing are:
–The lms processes are the Global Cache Service(GCS) background processes in the instance
-Blocks can exist in more than one instance at a time.
-If an instance is requested to transfer a dirty block (a dirty block is a block that has been modified but not yet written to disk) to another instance in exclusive mode it keeps a past image of the block. This past image is basically a copy of the block as the holding instance last knew it before it transferred it to the requesting instance. This past image is used for recovery. Once the most recent copy (the master copy) of the dirty block is written to disk by dbwr the past images can and will be discarded. Note that PI’s can be used for a consistent read of a block as this saves having to build a copy from the rollback segment. The important thing to note is that an instance will always create a PI version of a dirty block before sending it to another instance if the requesting instance wants it in exclusive mode. If an instance requests the master block for read (consistent or current) there is no need for the holding instance to keep a PI as the requesting instance is not going to change the block
-The most recent copy (the master copy or current block) of a block contains all changes made to it by transactions, regardless of which instance the change occurred on and whether the transaction(s) has committed or not
-A block is assigned a role and mode and a status (clean or dirty)
-The block is held in a local role if it is only held in one SGA, it is held in a global role if it is held in more than one SGA
-The block can be held in null, shared or exclusive mode. Null mode means that the instance has no access rights on the blocks, shared mode means that the instance can read the block and exclusive mode means that the instance can write to the block. Many instances can have the same block in null or shared mode, but only one can have it in exclusive mode (as exclusive mode implies the instance wants to modify the block). To view the current mode of the block in an instance view v$bh.status. The following applies to the state of the blocks:
Global Enqueue Service(GES)
Global Enqueue Service(GES) manages all non-cache fusion resource requests and tracks the status of all enqueuing mechanisms. The GES only does this for resources that are accessed by more than one instance. The primary resources that the GES controls are dictionary cache locks and library cache locks. The GES manages the interinstance communication that occurs between the instances for these resources. These resources exist in single instance, the difference being that in RAC these must be coordinated between all instances in the cluster.
Dictionary cache locks – The data dictionary must be consistent across all nodes, if a table definition is changed on one instance the Global Enqueue Service ensures that the definition is propagated to the dictionary cache on all the other instances.
Library cache locks – These locks are held by sessions whilst they parse or execute SQL or PLSQL statements. These locks prevent other sessions from modifying the definitions of objects in the data dictionary that are being referenced by the statement that is currently parsing or executing.
Oracle RAC architecture diagram
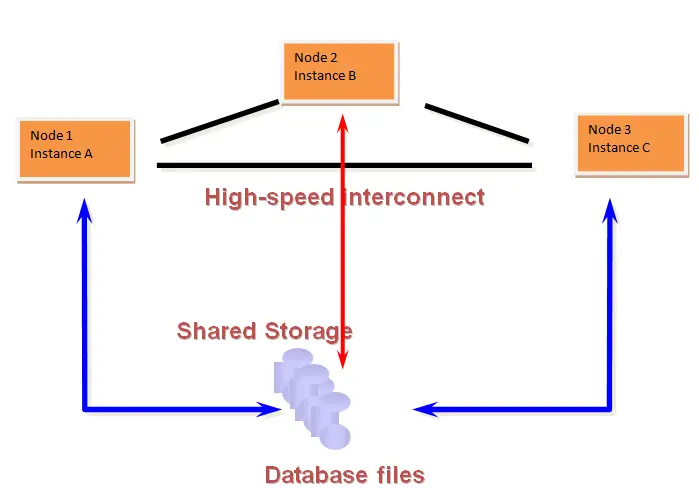
BACKGROUND PROCESSES IN RAC
Each instance in a RAC configuration has the same background processes as a single instance database, however there are extra background processes evident in a RAC enabled instance, these are mainly related to the Global Cache Service(GCS) and the Global Enqueue Service(GES):
LMS processes – These are the processes for the Global Cache Service. These processes are responsible for transferring blocks between instances and maintaining the Global Resource Directory to reflect the modes and roles the blocks are held in on each instance. A block can exist in more than one instance at a time, but the Global Cache Service controls who has what version of the block thereby ensuring that the most up to date block (the master copy) is always the one that is updated. All other versions of the block will be past images or read consistent versions of the block.
LMON – Global Enqueue Service Monitor
This process monitors global enqueues and resources across the cluster and performs global enqueue recovery operations. LMON also handles recovery associated with global resources and can detect instance failure of other nodes
LMD – Global Enqueue Service Daemon
This process manages global enqueue and global resource access. Within each instance, the LMD process manages incoming remote resource requests
LCK – This is the lock process and makes up part of the Global Enqueue Service. It manages non-Cache Fusion resource requests such as library and dictionary cache requests
DIAG – This is diagnostic daemon.Captures diagnostic information related to instance process failures.
To view all the background processes (RAC and non-RAC) evident in an instance:
SQL> select * from v$bgprocess where paddr ‘00’
STORAGE SYSTEM FOR ORACLE RAC
In a RAC environment all instances need to be able to write to the same datafiles simultaneously. There are 2 ways to do this, use Shared RAW devices on which we create the ASM instances on all the servers in the cluster or using Cluster File-system.
All Reads for ASM(Automatic Storage Management)
- Oracle ASM (Automatic Storage Management ) Introduction and How it works
- How to prepare the Oracle ASM disks
- Oracle ASM Diskgroups : Create and Alter diskgroup
- How ASM Failure Groups and CSS provides high availability
- ASM Initialization Parameters: ASM_DISKSTRING,ASM_DISKGROUPS
- How Oracle ASM Rebalance works
- ASM Lesson 7:ASM Metadata
- Oracle ASM Lesson 8: How to move database to ASM storage
- ASM best practice to add disk
Datafiles and tempfiles
All datafiles and tempfiles must reside on shared disks(ASM). The first instance to start will verify that it can read all datafiles identified in the control file. This must be done so that the first instance to start can determine whether instance or media recovery is required or not, this behavior is no different to single instance. However, instances that join the cluster at a later date can operate even if they cannot access all the files, they will simply raise an error when an attempt is made to access the file.
Control files
The control files must be on shared disks and must be accessible by all instances at startup time as determined in the parameter file.
Redo log files and archived logs
On RAC each instance must write to its own set of redo logs. This set is called a thread of redo. All threads of redo must reside on shared disks. The instance gets its thread of redo at startup time as determined by the thread parameter. If an instance cannot get its thread of redo it will fail to open. Each redo group will still be uniquely numbered at the database level and will be multiplexed or mirrored, just as in single instance. The only difference is that in RAC each redo group belongs to a thread, and only the instance specifying that thread number at startup time will write to the redo groups in that thread.
Each instance can, however, read all threads of redo. This is to facilitate instance recovery i.e if instance a fails then instance b will read instance a’s thread of redo to recover the failure. This must happen so that the consistency and integrity of the database is maintained if one instance fails. In order to facilitate instance recovery all redo files must reside on shared disks.
Archived log files are generated by each thread of redo and are uniquely identified by the thread number that we include in the log_archive_format and the sequence number which is unique for each instance. Archived_log can be on the local filesystem or shared filesystem.
Sequences
Sequences are held on disk. Even in single instance many DBA’s cache sequence numbers to avoid contention for the sequence. We cache most sequences in RAC to avoid contention on the sequence. If you have a high cumulative wait time in v$enqueue_stat on the SQ enqueue (the sequence number enqueue) then you should consider caching enqueues. RAC does support CACHING and ORDERING of sequence numbers.
Undo management
Undo/rollback datafiles must reside on RAW devices. If you use MANUAL undo then each instance must specify unique rollback segments in the instance specific parameter file. If you use AUTOMATIC undo then each instance must specify a separate tablespace, this tablespace must be available and of type UNDO. All instances in a RAC cluster must run in the same UNDO mode i.e you can’t have one running AUTOMATIC undo and another running MANUAL undo. If you are using AUTOMATIC undo monitor v$undostat for statistics.
To see if the oracle home is RAC enabled issue the following SQL:
select * from dba_registry
where comp_id = ‘RAC’;
To relink an oracle home with RAC disabled or enabled:
cd $ORACLE_HOME/rdbms/lib
make –f ins_rdbms.mk rac_off install OR
make –f ins_rdbms.mk rac_on install
Oracle RAC parameters
instance_number
instance_group
thread
cluster_database
cluster_database_instances
cluster_interconnects
remote_listener
local_listener
parallel_instance
max_commit_propagation_delay
For example here are parameter in 3 instance RAC
*.cluster_database=true
*.cluster_database_instances=3
*.compatible=’11.2.0.4′
*.undo_management=’AUTO’
INST1.instance_number=1
INST1.instance_name=rac1
INST1.thread=1
INST1.undo_tablespace=’UNDO1′
INST2.instance_number=2
INST2.instance_name=rac2
INST2.thread=2
INST2.undo_tablespace=’UNDO2′
INST2.instance_number=3
INST2.instance_name=rac3
INST2.thread=3
INST2.undo_tablespace=’UNDO3′
Parameters That Must Have Identical Settings on All Instances
Certain initialization parameters that are critical at database creation or that affect certain database operations must have the same value for every instance in an Oracle RAC database. Specify these parameter values in the SPFILE or in the individual PFILEs for each instance. The following list contains the parameters that must be identical on every instance:
COMPATIBLE
CLUSTER_DATABASE
CONTROL_FILES
DB_BLOCK_SIZE
DB_DOMAIN
DB_FILES
DB_NAME
DB_RECOVERY_FILE_DEST
DB_RECOVERY_FILE_DEST_SIZE
DB_UNIQUE_NAME
INSTANCE_TYPE (RDBMS or ASM)
PARALLEL_EXECUTION_MESSAGE_SIZE
REMOTE_LOGIN_PASSWORDFILE
UNDO_MANAGEMENT
The following parameters must be identical on every instance only if the parameter value is set to zero:
DML_LOCKS
RESULT_CACHE_MAX_SIZE
RAC wait events and Performance tuning
Analyzing and interpreting what sessions are waiting for is an important method to determine where time is spent. In Oracle RAC, the wait time is attributed to an event which reflects the exact outcome of a request. For example, when a session on an instance is looking for a block in the global cache, it does not know whether it will receive the data cached by another instance or whether it will receive a message to read from disk. The wait events for the global cache now convey precise information and waiting for global cache blocks or messages is:
- Summarized in a broader category called Cluster Wait Class
- Temporarily represented by a placeholder event which is active while waiting for a block, for example:
gc current block request
gc cr block request
- Attributed to precise events when the outcome of the request is known, for example:
gc current block 3-way
gc current block busy
gc cr block grant 2-way
Most important wait events for Oracle RAC are categorized as
A)Block-oriented
gc current block 2-way
gc current block 3-way
gc cr block 2-way
gc cr block 3-way
B)Message-oriented
gc current grant 2-way
gc cr grant 2-way
C)Contention-oriented
gc current block busy
gc cr block busy
gc buffer busy acquire/release
D)Load-oriented
gc current block congested
gc cr block congested
Lets go one by one one each of these
A) Block-Oriented Waits
1. gc current block 2-way
Here requesting instance request from data block for DML(current) from Master.If master is the holder of that data block and also has already modified that block.Then master will retain PI block for itself.Master will also flush respective redo log to log file before sending CURRENT block to requesting instance. In this whole process requesting instance will wait in “GC CURRENT BLOCK 2-WAY”
2. gc current block 3-way (write/write with 3 nodes)
here Requesting instance request any data block in CURRENT MODE for dml(current) from Master.If master is not holder of that data block and that data block is globally available on another instance. Master will send a message to the current holding instance to relinquish ownership (Downgrade lock). The holding instance retain the PI of that data block and then serve to the requesting instance.Holding instance will also flush respective redo log to log file before sending CURRENT block to requesting instance.In this whole process requesting instance will wait in “GC CURRENT BLOCK 3-WAY”
3. gc cr block 2-way (read/read or write/read with 2 nodes)
Here Requesting instance request any CR data block for select from Master.If master is the holder of that data block and also has already modified that block.
Then master will prepare CR copy of that data block (using undo).And then Master instance serve CR block to the requesting instance.
In-case master is the holder of that data block and has not already modified that block.then Master instance serve CR block to the requesting instance immediatly.
In this whole process requesting instace will wait in “gc cr block 2-way”
4. gc cr block 3-way (read/read or write/read with 3 nodes)
This wait event is exactly same as “gc cr block 2-way”, only the difference is that here 3 or more than 3 instances are involved.
TroubleShooting
Incase we are seeing high average wait times on these events, then we can check following
1) Check for High load on the server. Check for CPU shortages, long run queues, scheduling delays
2) Network issue. There could be misconfiguration and instance are using public instead of private interconnect for message and block traffic
3) The object statistics enable us to identify the indexes and tables which are shared by the active instances. We can do tuning on those to reduce the waits.We can also think about .Segregation means try to locate all select query on one node and all DML on another node
B) Message-Oriented Waits
1. gc current grant 2-way
Here An instance request any data block in CURRENT MODE for dml(current) from Master.If the data block is not cached on any instance even on master too, then master instance will send a message to the requesting instance granting the EXCLUSIVE lock.In this process requesting instance will wait in “GC CURRENT BLOCK 2-WAY”
Now after that Requesting instance will read data block from disk and do the physical I/O.
2. gc cr grant 2-way
Here An instance request any data block in CR MODE for select from Master.If the data block is not cached on any instance even on master too, then master instance will send a message to the requesting instance granting the SHARED lock.Meanwhile requesting instance will wait in “GC CR BLOCK 2-WAY”
Now after that Requesting instace will read data block from disk and do the physical I/O.
If the time consumed by these events is high, then it may be assumed that the frequently used SQL causes a lot of disk I/O (in the event of the cr grant) or that the workload inserts a lot of data and needs to find and format new blocks frequently (in the event of the current grant).
C) Contention-Oriented Waits
1.gc current block busy
Here An instance request for any data block in current mode, it send a request to the master.If master is the holder of that data block and also has already modified that block.Then master will retain PI block for itself.Master will also flush respective redo log to log file before sending CURRENT block to requesting instance.
Now the block transfer delayed on requsting instance.
In this whole process requesting instance will wait in “gc current block busy”
2) gc cr block busy
This event is the same as a “gc current block busy”
Troubleshooting and Reason for High Wait time
The contention-oriented wait event statistics indicate that a block was received which was pinned by a session on another node, was deferred because a change had not yet been flushed to disk or because of high concurrency, and therefore could not be shipped immediately. A buffer may also be busy locally when a session has already initiated a cache fusion operation and is waiting for its completion when another session on the same node is trying to read or modify the same data. High service times for blocks exchanged in the global cache may exacerbate the contention, which can be caused by frequent concurrent read and write accesses to the same data.
We can Tune LGWR
Do Appropriate Application Partitioning
Tune N/w
D) Load-Oriented Waits (LMS)
1. gc current block congested
Whenever any instance request for any data block in any mode, this request will be served by MASTER NODE of that data block. LMS process running on master node will provide data block to the requesting instance LMS process.
Now LMS process running on both the nodes are highly loaded so there would be wait event “”gc current block congested
2. gc cr block congested
This event is the same as a “gc current block congested”.
Trouble-Shooting
The load-oriented wait events indicate that a delay in processing has occurred in the GCS, which is usually caused by high load, CPU saturation and would have to be solved by additional CPUs, load-balancing, off loading processing to different times or a new cluster node.
To find locks in Oracle RAC
SELECT inst_id,DECODE(request,0,'Holder: ','Waiter: ')||sid sess,
id1, id2, lmode, request, type
FROM GV$LOCK
WHERE (id1, id2, type) IN
(SELECT id1, id2, type FROM gV$LOCK WHERE request>0)
ORDER BY id1, request
;
Some Imp points
- Cache Fusion:Cache Fusion is a new parallel database architecture for exploiting clustered computers to achieve scalability of all types of applications. Cache Fusion is a shared cache architecture that uses high speed low latency interconnects available today on clustered systems to maintain database cache coherency. Database blocks are shipped across the interconnect to the node where access to the data is needed. This is accomplished transparently to the application and users of the system. As Cache Fusion uses at most a 3 point protocol, this means that it easily scales to clusters with a large numbers of nodes
2.The LMD and LMS processes are critical RAC processes that should not be blocked on CPU by queuing up behind other scheduled CPU events
3 v$ges_statistics view returns various statistics on the Global Enqueue Service.
4.gv$lock view will show all the locks held by all the instances
Infrastructure for Oracle Real Application clusters
Oracle RAC require clusterware for its functioning.Clusterware has two main functions; to provide node membership services and to provide internode communications.
Oracle RAC provides oracle clusterware software for Oracle RAC.
Oracle Clusterware includes a number of background processes that are
implemented in Linux/Unix as daemons, including the following:
•Cluster Synchronization Service (CSS)
•Cluster Ready Services (CRS)
•Event Management (EVM)
These background processes communicate with similar components on other instances in the same database cluster. They also enable communication between Oracle Clusterware and the Oracle database. Under Linux, each daemon can have multiple threads, each of which appears as a separate operating system process.
On Unix platforms an additional daemon process called OPROCD is configured. This process is locked into memory to monitor the cluster and provide I/O fencing. It provides similar functionality to the hangcheck timer on Linux. OPROCD performs its check, stops running, and if the wake up is beyond the expected time, then OPROCD reboots the node. An OPROCD failure results in Oracle Clusterware restarting the node.\
All Reads about Cluster
- What is Oracle Clusterware?
- How to setup diag wait in cluster
- Cluster command in Oracle clusterware 10g , 11g and 12c
- How to Recreate Central Inventory in Real Applications Clusters
- why-database-not-startup-automatic in 11gR2 cluster
- How to add any node to Oracle RAC cluster in 10g and 11g
- Oracle Flex Cluster 12c
- How to find RAC interconnect information
- What is voting disks in RAC
- Virtual IP Addresses : VIP in Oracle RAC
- Single Client Access Name (SCAN)
Recommended Reading